Algorithmen, die lernen, aber nichts verstehenUnderstanding Digital Capitalism III | Teil 3
18.12.2017 • Gesellschaft – Text: Timo Daum, Illustration: Susann Massute
Warum Tom Sawyer ein Pionier der Künstlichen Intelligenz ist, Google uns mal wieder ausnutzt und das deep learning eine Mogelpackung ist: In der neuen Folge von »Understanding Digital Capitalism« untersucht Timo Daum die grundlegenden Missverständnisse unserer Algorithmen-Hörigkeit. Ist deep learning wirklich für die Tonne? Würde Watson nicht andauernd Jeopardy gewinnen, könnte man die Frage wirklich stellen.
Was bisher geschah:
In der vorherigen Folge ging es um Intelligenz und die Schwierigkeit, gar Unmöglichkeit, diese adäquat zu definieren. Und es ging um Alan Turing, der das damals schon genauso sah und deshalb seinen berühmten Test entwickelte – eine Art queeres Imitationsspiel, das womöglich als Inspiration für Judith Butlers Gender-Theorie gedient haben mag. Da die Begriffe Intelligenz und erst recht Künstliche Intelligenz so ausgesprochen schwammig und irreführend sind, beschloss ich – auch wenn diese Entscheidung unter SEO-Aspekten dem medialen Abseits entspricht – nicht mehr von Künstlicher Intelligenz zu sprechen, sondern das Ganze Software 2.0 nennen und dafür gleich eine diesmal hoffentlich taugliche Definition zu liefern: Unter dem Begriff Software 2.0 sind Algorithmen zu verstehen, die sich in ihrem Code selbständig ändern können bzw. deren Zweck es ist, aus vielen Daten Modelle abzuleiten und daraus dann Schlüsse zu ziehen und Aktionen einzuleiten. Jetzt aber zum Thema dieser Woche, einem derzeit angesagten Teilgebiet der KI (jetzt hab‘ ich’s doch wieder gesagt): machine learning.
TYP1-Maschinen
Es gibt Maschinen, die für eine bestimmte Aufgabe konstruiert sind und sonst nichts können: Ein Fön kann fönen, sonst nichts. Ich kann ihn zwar zweckentfremden, also damit beispielsweise auch ein Schloss enteisen, trotzdem hat er einen sehr eingeschränkten Anwendungsbereich – es handelt sich sozusagen um eine eindimensionale sole-purpose maschine. Auch eine Waschmaschine, die zwar einen Computerchip enthält, verschiedene Programme ablaufen lassen kann, oder auch ein Auto ist für eine Sache inklusive einiger Varianten konstruiert. Die nenne ich TYP1-Maschinen.
TYP2-Maschinen
Dann gibt es Maschinen, die nicht nur ein Problem oder einige wenige lösen können, sondern eine ganze Klasse. Die Maschinen sind programmierbar. Das bedeutet: Stattet man sie mit einem neuen Programm aus, sind sie auch in der Lage, neue Probleme zu lösen – die universal Turing machines, Computer genannt. Programmierbare Computer, die unterschiedliche Software abspielen können, also nicht auf ein Programm beschränkt sind wie bspw. ein Taschenrechner, können nun viele Klassen von Problemen lösen. Die Möglichkeiten dabei sind im Prinzip unendlich, weil es ja unendlich viele Möglichkeiten gibt, Software zu programmieren. Trotzdem kann das Gerät eben nur das, was über einen Programmcode eingelesen worden ist, selbst nach der x-ten Rechnung, dem x-ten Video ist das Gerät bzw. die eingesetzte Software in ihrem Funktionsumfang exakt gleich geblieben, weder besser noch schlechter geworden: TYP2-Maschinen oder auch Software 1.0.
„Watson kombiniert Künstliche Intelligenz (KI) und anspruchsvolle analytische Software. Das ist wie eine Karosserie lackieren auf der einen Seite (können Roboter schon seit den 70ern) und Autofahren auf der anderen (lernen sie erst jetzt).“
TYP3-Maschinen
Im Jahr 1997 besiegte erstmals ein Computer, IBMs Deep Blue, den amtierenden Großmeister im Schach, Garry Kasparow. Vierzehn Jahre später schlug IBM wieder zu: Diesmal wurde die Quiz-Show Jeopardy (Wer wird Millionär) von IBM Watson souverän gewonnen. Zwischen diesen beiden Aufgaben liegen Welten. Das Schachspiel beruht auf wenigen, glasklaren Regeln, und die Strategie im Schach ist für einen Computer leicht zu lösen: so viele Züge wie möglich antizipieren und die daraus entstehenden Stellungen evaluieren. Die sizilianische Eröffnung lässt sich leicht formalisieren, das ist ein Paradebeispiel für Software 1.0. Aber wie bringt man einem Computer bei, die richtige Antwort auf eine Scherzfrage zu finden? Etwa diese hier: Wessen Ansprüche sollen hierzulande gesetzlich neu geregelt werden? A: Bargeldeltern, B: Scheinväter, C: Münzmütter, D: Kreditkartenfamilien.

Watson spielt eine Runde „Jeopardy“. Foto: Engadget
Deep Blue war einfach nur ein Rechner, den leistungsmäßig heute jedes Smartphone in die Tasche steckt. IBMs Watson hingegen ist eine Software-Plattform, die natürliche Sprache versteht, Ironie detektieren und unterschiedlichste Strategien parallel verfolgen und evaluieren kann. Watson kombiniert Künstliche Intelligenz (KI) und anspruchsvolle analytische Software. Das ist wie eine Karosserie lackieren auf der einen Seite (können Roboter schon seit den Siebzigern) und Autofahren auf der anderen (lernen sie erst jetzt). Apple-CEO Tim Cook hat gerade erst bestätigt, dass seine Firma an Software für das autonome Fahren arbeite und dieses Projekt als „die Mutter aller KI-Projekte“ bezeichnet. Im Unterschied dazu ist KI-Software oder Software 2.0 in der Lage, Aufgaben zu lösen, für die es nicht programmiert worden ist. Dazu muss die Software lernen, und lernen heißt, aus sehr vielen Daten Modelle ableiten: TYP3-Maschinen und Software 2.0.
Maschinen, die dazulernen
In den letzten Jahren hat die Disziplin Auftrieb bekommen, zahlreiche KI-Anwendungen sind bis ins Alltagsleben vorgedrungen. Insbesondere im Bereich der Bilderkennung, beim Autonomen Fahren oder bei Sprach-Assistenten wie Apples Siri oder Amazons Alexa, die natürliche Sprache verstehen und generieren können, sind erhebliche Fortschritte erzielt worden. Der amerikanische KI-Pionier Arthur Samuel prägte 1959 den Begriff Machine Learning für Software, in die selbstlernende Verfahren implementiert sind oder, wie er es selbst formulierte, „mit der Fähigkeit, zu lernen, ohne dafür explizit programmiert worden zu sein“. Beim maschinellen Lernen analysiert ein Programm eine große Menge an Daten, versucht Strukturen zu erkennen und Modelle zu generieren, aus denen dann Schlussfolgerungen gezogen werden können.
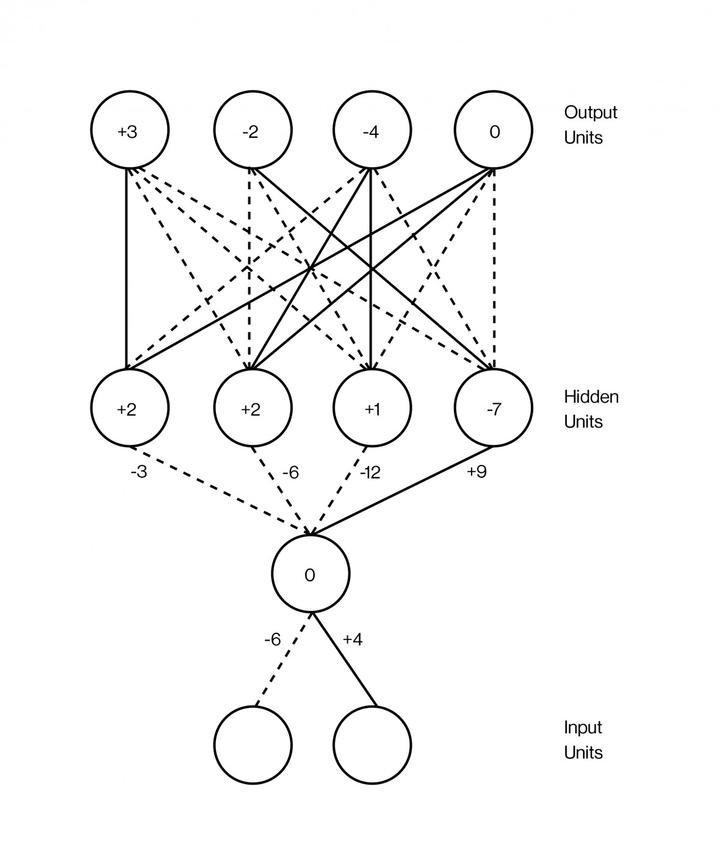
Abb: Modell für deep learning aus der bahnbrechenden Arbeit von Geoffrey Hinton et. al. (1986)
Deep Learning oder: Wie lernt das Gehirn?
Machine learning versucht den menschlichen Neo-Cortex nachzubilden. Das nennt man dann künstliche neuronale Netze (ANNs) oder konnektionistische Systeme. Diese Systeme erlernen Aufgaben durch Betrachtung von Beispielen, im Allgemeinen ohne aufgabenspezifische Programmierung. Das technologiekritische Redaktionskollektiv çapulku beschreibt die Funktionsweise schön prägnant am Beispiel von Bilderkennung: „Eine erste Schicht ‘Neuronen’ unterscheidet helle und dunkle Pixel und reicht das Ergebnis weiter an eine zweite, die in der Lage ist, auf dieser Basis Konturen zu entdecken. Eine dritte Schicht kann eine weitere Klassifizierung dieser Konturen durch einen Vergleich mit einer Musterdatenbank vornehmen usw. Das Lernen durch vorklassifizierte Trainingsbeispiele verändert dabei die Synapsen, also nicht nur die Vergleichsmusterdatenbank, sondern die logische Verknüpfung zwischen den jeweiligen neuronalen Schichten.“
Verblüffenderweise ist das Konzept für deep learning vergleichsweise uralt. Geoffrey Hinton und Kollegen erfanden das Prinzip der „Rückpropagation“ (back propagation) vor über drei Jahrzehnten. Um bei diesem wichtigsten Verfahren zum Trainieren von künstlichen neuronalen Netzen dessen verborgene Schichten sinnvoll optimieren zu können, muss zu allen Trainingsmustern die gewünschte Ausgebe bekannt sein. Hinton selbst hält heute gar nicht mehr so viel von seinem alten Prinzip und findet alle aktuellen KI-Fortschritte demensprechen schal, wie er dem MIT gegenüber offenbarte. Er hält diese Form „überwachten oder angeleiteten Lernens“ mittlerweile für überholt und neue Formen nicht-überwachten Lernens für viel interessanter.
Montagsmaler für die Maschine oder Tom Sawyer, King Of Gamification
Wir erinnern uns: In Mark Twains berühmtem Kinderbuch Tom Sawyer und Huckleberry Finn von 1876 schickt Tante Polly eines Morgens Tom hinaus, um den Gartenzaun weiß zu tünchen. Etwas später kommt Ben Rogers, ein anderer Junge in Toms Alter, vorbei. Tom überzeugt Ben, dass es eine große Freude sei, einen Zaun zu streichen, und nach einigem Verhandeln willigt er ein, Tom seinen Apfel als Gegenleistung für das Privileg zu geben, am Zaun zu arbeiten. Die Erfindung des Gamification-Ansatzes!
Die Firma Google hat immer mal wieder Zäune zu streichen, jüngst baten sie ihre „Freunde“ – sprich uns alle –, doch an einer tollen Sache mitzuwirken, nämlich dem Trainieren einer ihrer Lernmaschinen: Google hat einen Algorithmus programmiert, der Zeichnungen erkennen soll. Also rufen sie einfach hunderttausende Ben Rogers auf, doch welche zu zeichnen – bitteschön!

Bild: Ausgewählte Schädel (Bild: Google)

By The original uploader was Sethwoodworth at English Wikipedia - Transferred from en.wikipedia to Commons by Mardetanha using CommonsHelper., CC BY 3.0, Link
Minskys Koffer
Marvin Minsky, einer der KI-Pioniere und Teilnehmer des Gründungs-Hangouts am Dartmouth College, Hanover, New Hampshire (siehe Teil 1 dieser UDC-Staffel), nannte Wörter, die eine Vielzahl an Bedeutungen haben können, so genannte „Koffer-Wörter“ (suitcase words). Lernen ist ein solches Koffer-Wort: Fahrrad fahren lernen, eine Sprache lernen, Programmieren lernen, Achtsamkeit lernen – denkbar unterschiedliche Inhalte und Formen des Lernens. Maschinelles Lernen unterscheidet sich von einem intuitiven Begriff, oder der Art und Weise wie wir Menschen lernen, erheblich. Maschinelles Lernen ist aber auch sehr spröde und erfordert viel Vorbereitung durch menschliche Forscher oder Ingenieure, spezielle Programmierung und spezielle Trainingsdatensätze.
Das maschinelle Lernen ist nicht zu vergleichen mit dem schwammartigen Aufsaugen von Information, deren Rekombination und Abstraktion, die wir von uns selbst kennen. Wenn Menschen hören, dass ein Computer den Weltschachmeister (1997) oder einen der weltbesten Go-Spieler (im Jahr 2016) schlagen kann, neigen sie dazu, zu glauben, dass sie das Spiel „spielen“, wie es ein Mensch tun würde. Natürlich hatten diese Programme in Wirklichkeit keine Ahnung, was ein Spiel ist. Sie sind zwar besser im Spiel, stellen sich aber gleich wieder ganz blöd an, sobald man die Regeln ein wenig ändert. Für einen Menschen ist das kein Problem, die KI kann ihr gesamtes deep learning hingegen in die Tonne treten und muss wieder ganz von vorne anfangen.
Fazit
Maschinelles Lernen wird immer besser, verbeitet sich rasen und wird so schließlich auch zum ökonomischen Faktor – Amazon macht 30 Prozent seines Umsatz mit Käufen, die durch das Klicken auf vorgeschlagene Produkte zu Stande gekommen sind. Hinter Amazons Vorschlägen steckt eine „maschinelle Lernempfehlungsmaschine“, und die von einer weiteren KI, nämlich mit Google Translate generierten Übersetzung von „machine learning recommendation engine“.
Quellen und Links
- Arthur L. Samuel, "Some Studies in Machine Learning Using the Game of Checkers". IBM Journal of Research and Development, 1959
- David E Rumelhart, Geoffrey E Hinton, Ronald J Williams, Learning representations by back-propagating errors, in: Nature, Vol. 323, 1986, S. 533-536
- James Somers, Is AI Riding a One-Trick Pony?, MIT Technology Review, 29.9.2017
- DISRUPT! Widerstand gegen den technologischen Angriff. Unrast, Münster 2017.
- Timo Daum, Künstliche Intelligenz, in: Junge Welt, Ausgabe vom 22.11.2017
Zur Übersicht aller bisherigen Texte der Reihe »Understanding Digital Capitalism«.




