Zehn Dinge, die man über Google wissen sollteUnderstanding Digital Capitalism | Teil 9
29.6.2015 • Gesellschaft – Text: Timo Daum, Illustration: Susann Massute
Nachdem uns Timo Daum die Verbindung von Hippie-Ideologie und marktradikalem Unternehmertum im Silicon Valley nähergebracht hat, erläutert er uns heute Geschichte und ökonomische Struktur der Suchmaschine Google. Er zeigt auf, wie Google Kapital durch Informationsverarbeitung generiert und nimmt uns mit auf einen historischen Streifzug. Von den Informatik-Vorreitern Alan Turing und Claude Shannon bis zur satirischen Kritik der heutigen Big-Data-Konzerne in Dave Eggers Roman „The Circle“.
1. Was macht Google eigentlich so besonders?
Google produziert nichts. Sie bauen keine Computer, verlegen keine Kabel. Sie erzeugen auch keine neue Informationen oder Inhalte wie etwa ein Filmstudio oder eine Zeitung. Sie machen nichts anderes, als im World Wide Web ohnehin vorhandene und frei zugängliche Informationen für uns in Ergebnislisten aufzubereiten – vermittelt durch das vielleicht berühmteste und wichtigste Interface der digitalen Welt: Google Search.
Google ist ein Paradox: Es ist eines der mächtigsten Unternehmen der Welt. Eine Aktiengesellschaft mit dem Ziel, Profit für ihre Aktionäre zu erwirtschaften. Gleichzeitig haben Sie den Anspruch, die Informationen der Welt kostenlos und für alle zur Verfügung zu stellen: „Google hat einen Weg gefunden mit Überfluss Geld zu verdienen, während alle anderen Medien-Unternehmen der Welt versuchen, Verknappung zu produzieren. Dafür sollten wir dankbar sein“, meint der Kulturhistoriker und Medienwissenschaftler Siva Vaidhyanathan. Wir schauen uns das mal genauer an!
Das vielleicht wichtigste Interface des WWW – das Suchfenster von Google, unser Tor zur digitalen Informationswelt.
2. Was bedeutet Google eigentlich?
2015 werden so viele neue Informationen digital entstehen wie in den letzten 30.000 Jahren – die gespeicherte Information wächst exponentiell. Die Bibel ist in etwa fünf Megabyte groß, heute werden 132 Petabyte (Milliarden Megabyte) pro Monat neu generiert – was gestern viel war, ist heute wenig. Keine Angst vor großen Zahlen – das ist das grundlegende Credo von Google, daher auch der Firmenname, der sich von Gogol ableitet, einer Eins mit hundert Nullen hintendran.
Alan Turing war einer der ersten, der die Angst vor der großen Zahl überwand – mit Hilfe einer Maschine. Die Entschlüsselung der Enigma, einer Art Codier-Schreibmaschine, mit der die Nazis ihre Funksprüche im Zweiten Weltkrieg verschlüsselten, galt als unknackbar angesichts ihrer Milliarden Kombinationsmöglichkeiten. Anstatt das Handtuch zu werfen befand Turing: Das sind so viele, das kann nur eine Maschine lösen! In dieser Tradition des digitalen Solutionism (siehe Kritik der Kalifornischen Ideologie), steht Google: Was unmöglich erscheint, erfordert nur eine noch größere Maschine, einen noch besseren Algorithmus.

Die Anti-Nazi-Waffe des Informatikers: Die Turing-Bombe. Quelle: Wikimedia
Die Suchmaschine Google begann 1996 als Forschungsprojekt der späteren Firmengründer Sergej Brim und Larry Page in Stanford: The Anatomy of a Large-Scale Hypertextual Web Search Engine. Die Google.com-Domain gibt es seit 1997. 1998 waren 30 Millionen Webseiten registriert, im Jahr 2000 waren es schon eine Milliarde. Heute ist Google.com ist die meistbesuchte Website weltweit. Google betreibt über eine Million Computer in Datenzentren überall auf der Welt und verarbeitet 5,7 Milliarden Suchanfragen täglich.
3. Würden wir ohne Google gar nichts mehr finden?
Im Internet gibt es viel mehr als nur das Web: E-Mail, Up- und Downloads, Videokonferenzen, Streaming, Filesharing uvm. Und auch im WWW finden wir vieles, ohne die Suche bemühen zu müssen: Wir kennen die URL auswendig oder können sie erraten, wir bekommen einen Link geschickt, den wir nur anklicken müssen, wir werden weitergeleitet etc. Für den Rest ist die Suche allerdings das probate Mittel.
Es gibt keine zentrale Instanz im Internet, die wüsste, welche Seiten es auf welchen Servern gibt. Das WWW besteht aus vielen HTML-Dokumenten, die über Links miteinander verbunden sind. Das war Tim Berners-Lees Idee um Ordnung in das Chaos wissenschaftlicher Dokumente in Rechnernetzen zu bringen: Hypertext, also schlicht Text-Dokumente, die Verweise (Links) zu anderen Texten enthalten.
Die rettende Liane im wuchernden Daten-Dschungel: Hypertext.
4. Wie haben wir eigentlich vor Google gesucht?
Das Suchen von Web-Inhalten anhand von Stichwörtern ist eine relativ junge Kulturtechnik. Lange Zeit wurden Portale benutzt, Einstiegsseiten wie AOL oder Yahoo, die eine Art systematische Kategorien-Listen (Kino, Sport, Nachrichten etc.) anboten. Diese Portale sind durch das Aufkommen von Suchmaschinen aus der Mode gekommen.

AOL wartete in den 90ern mit einem Main Menu statt Stichwortsuche auf. Quelle: ugo.
5. Wie funktioniert eigentlich eine Suchmaschine?
Eine Suchmaschine besteht aus drei Teilen, dem Crawler, dem Index und dem Interface. Zunächst durchsuchen automatisierte Programme, sogenannte Web-Crawler, das WWW, indem sie sich von Link zu Link weiterhangeln. Alle Seiten, die sie dabei finden speichern sie in einer Liste ab, dem Index. Meta-Informationen wie Schlüsselwörter, Beschreibung, Überschriften werden mit aufgenommen. Suchmaschinen legen also einen periodisch aktualisierten Katalog aller Webseiten an.
Gibt jemand einen Suchbegriff in das Interface der Suchmaschine ein, wird dieser Index oder Katalog nach dem Suchbegriff durchsucht, nicht etwa das Netz selbst. Deshalb sind die Ergebnisse auch in Bruchteilen von Sekunden da. Ausgegeben wird eine Liste an Treffern mit Titel, Kurzbeschreibung und Verweis, das Ganze nach Relevanz sortiert. Was heißt relevant? Wie entscheidet die Suchmaschine, welche von den mitunter Millionen Treffern die besten sind und als erstes angezeigt werden sollten? Das Ranking der Seiten ermittelt der Suchalgorithmus aus der Häufigkeit des Auftauchens des Suchbegriffs in URL, Titel und Text der Seite.
Seiten werden hoch geranked, wenn der Suchbegriff häufig auf der Seite auftaucht. Missbrauchsmöglichkeiten sind so Tür und Tor geöffnet: Die Seite kann alle diese Kriterien erfüllen und trotzdem nicht das sein, was ich suche, sondern eine Seite, die etwas ganz Anderes enthält. Das war bis Mitte der 90er Jahre ein Problem aller Suchmaschinen, sie konnten nicht wirklich den Inhalt gefundener Seiten einschätzen. Auch die Suche nach abstrakten Begriffen, wie z.B. nach „Bibliographie“, lieferte keine zufriedenstellenden Ergebnisse, da Seiten, die etwa das Wort „Bibliographie“ im Quelltext enthalten, oft nicht das Gesuchte sind.
6. Warum ist Google eigentlich besser?
Die beiden Google-Gründer haben sich für ihre alternative Ranking-Methode von der wissenschaftlichen Community inspirieren lassen. Die hat ein ähnliches Problem: Wie kann die Qualität wissenschaftlicher Veröffentlichungen gemessen werden? Von zig Veröffentlichungen zu einem Thema – welches sind die relevanten? Antwort: Die, die am häufigsten zitiert werden. Eine Arbeit, die häufig zitiert wird, muss gut sein, das kann ich auch ohne die Arbeit gelesen oder gar verstanden zu haben, feststellen.
Google übernimmt diese Idee für das World Wide Web: Was in der Wissenschaft Zitate sind, sind hier Verlinkungen von anderen Seiten. Ein Link von einer anderen Seite auf meine eigene (Backlink) stellt eine Empfehlung dar. Google erstellt also einen Page-Rank, ohne den Inhalt der Seiten zu kennen, sondern durch die Analyse von Anzahl und Qualität der Backlinks. Dabei werden Links von Seiten, die selbst einen hohen Page-Rank haben, höher bewertet.
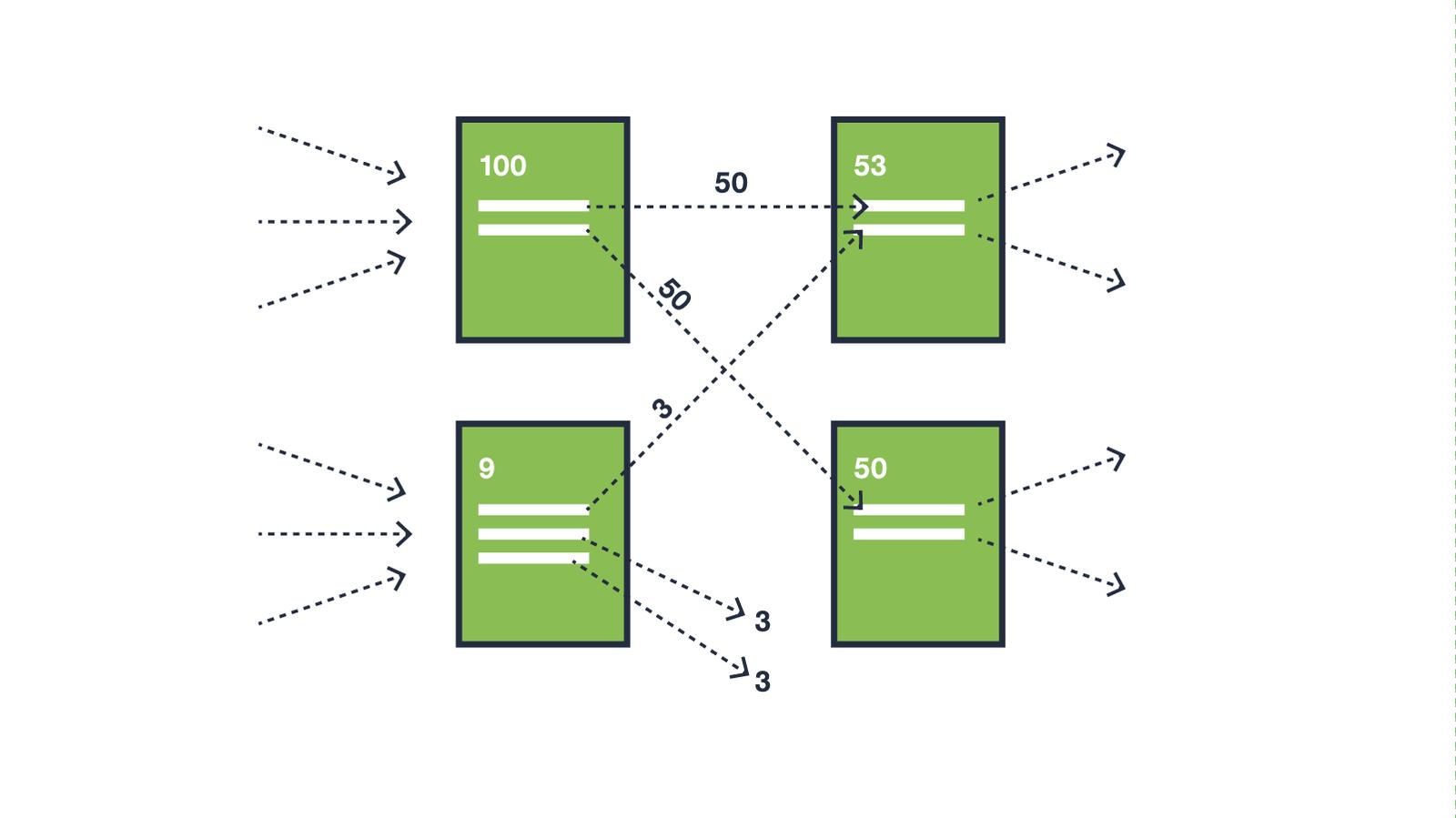
Wie sich unsere Suchergebnisse konstituieren: Vererbung von Page-Rank.
7. Sind Algorithmen eigentlich besser?
Googles Algorithmus hat sich den vorherigen Ansätzen als überlegen erwiesen, alle Suchmaschinen haben ihr Konzept übernommen. Googles Marktanteil liegt weltweit bei 85%, wobei es starke regionale Unterschiede gibt. Der Algorithmus wird ständig weiterentwickelt und ist abgesehen von der Grundidee natürlich Betriebsgeheimnis. Bei jeder Suche werden bis zu hundert Parameter (Signals) aufgezeichnet, um die Trefferlisten zu optimieren: Welches Ergebnis wird ausgewählt? Kommt der User zurück und sucht erneut, wird einer der vorgeschlagenen Begriffe gewählt uvm. Zusätzlich werden unsere vorangegangenen Suchen miteinbezogen.
Aber sind Algorithmen wirklich das Beste, wenn es um das Finden von Information geht? Selbst Online-Partnervermittlungen behaupten, dass sie mit ein paar Daten effektiv passende Lebenspartner finden können. Information als statistische Größe zu betrachten, und allein aufgrund einer großen Zahl von Daten die richtigen Suchergebnisse, den richtigen Partner, das beste Restaurant, etc. liefern zu können – das ist das Mantra von Big Data.

Der Vater der Suchmaschinenoptimierung Claude Shannon. Quelle: Computerhistory.
Diese Wahrscheinlichkeits-Perspektive auf Information geht auf Claude Shannon zurück. Shannon entwarf Ende der 40er Jahre eine mathematische Theorie, in der Information als statistische Größe angesehen und damit messbar und berechenbar wird. In seiner Theorie wird Information quantifizierbar und es ist kein Platz mehr für Wahrheit oder Unwahrheit: 2+2=5 enthält genauso viel Information wie 2+2=4. Er erfand auch gleich einen Namen für die Einheit für Information: Bit (binary digit).
Google & Co. haben die Philosophie von Shannon internalisiert und globalisiert: Lüge oder Wahrheit – der Algorithmus, das Ranking, die Wahrscheinlichkeit ist einzig relevant. Googles Monopolstellung führt zu einer eingeschränkten Sicht der Welt, alles drängt zum Licht bzw. zu den ersten Plätzen im Page-Rank. Mit Suchmaschinenoptimierung (SEO) ist ein ganzer Wirtschaftszweig entstanden, dessen Geschäft es ist, Informationen für Google relevanter erscheinen zu lassen. Was vielen gefällt, wird für relevant erklärt. Der Mainstream, das Altbewährte wird befördert gegenüber dem Neuen, der Nische.
8. Womit verdient Google eigentlich Geld?
Google erzielt 97% seines Umsatzes mit Anzeigen, die zusätzlich zu den organischen Ergebnissen angezeigt werden. Wie kann das sein, auf die Anzeigen klickt doch niemand? Als Werbetreibender kann ich Anzeigen für präzise definierte Situationen und Suchbegriffe buchen. Im Vergleich zu anderen Werbeformen wie Fernseh- und Radio-Spots oder Plakatwerbung hat diese Methode kaum Streuverluste und ist außerdem viel günstiger. Werbekunden können ganz fein Budget und Zielgruppe einstellen, bezahlt wird nur, bei „erfolgreicher Vermittlung“ sprich dem tatsächlichen Klick auf die Anzeige.
Werbetreibende können für jede Anzeige einen Höchstpreis festlegen und Seiten im Rahmen einer Echtzeit-Versteigerung zwischen konkurrierenden Werbekunden schalten. Das kann von Cent-Beträgen bis hin zu 86,64 Euro für den teuersten deutschen Suchbegriff „Wirtschaftsdetektei Frankfurt“ gehen. Für Google selbst sind das Schalten der Anzeigen, die Auktion der Anzeigenplätze, die Weiterleitung und das Dokumentieren leichte Aufgaben für automatisierte Algorithmen. Die Gebühren für Klicks können im Cent-Bereich liegen und trotzdem lohnt sich das noch.
9. Warum lohnt sich Suchmaschinen-Werbung eigentlich?
Ein Beispiel: Ein Snowboard-Laden aus Berlin möchte beim Suchwort „Snowboard“ eine Anzeige schalten, aber nur, wenn die Suchenden aus Berlin kommen. Tritt ein solches Ereignis ein, wird die Anzeige geschaltet. Bis jetzt kostet das noch nichts. Erst wenn tatsächlich auf die Werbung geklickt wird, wird maximal der vorher vereinbarte Betrag fällig.
Aus Erfahrung weiß nun der Werbetreibende, wie oft ein Kunde, der zur Tür reinkommt, auch tatsächlich was kauft. Diese sogenannte conversion rate, also der Bruchteil der Besucher der Website, die tatsächlich am Ende ein Snowboard kaufen, ist leicht zu ermitteln. Sind conversion rate und durchschnittlicher Umsatz pro Online-Kauf bekannt, kann genau kalkuliert werden, was für eine Anzeige ausgegeben werden kann, um innerhalb der Gewinnspanne zu bleiben.

Per Google Adwords werden aus Klicks Käufer.
10. Soll ich den Roman „The Circle“ lesen?
Der Roman „The Circle“ von Dave Eggers begleitet die junge Mae Holland, Angestellte beim Weltkonzern, genannt „The Circle“, einer futuristischen Melange aus Social Media und Tech-Company, eine Mischung aus Google, Facebook und Twitter. Die Firma wird von den „drei Weisen“, dem kumpelhafter Turnschuh-Chef-Typen Eamon Bailey, dem turbokapitalistischen Überflieger Tom Stenton und dem verschlossenen Gründer und Super-Nerd Ty Gospodinov geleitet. Die drei wirken wie personalisierte Aspekte Kalifornischer Ideologie und erinnern stark an Larry Page, Sergej Brin, Eric Schmidt und Ray Kurzweil von Google. Der fesselnde Roman skizziert einen Konzern, der megalomanisch-globalen Wohltäter, frenetischen Hyperkapitalismus und Big-Brother-Dystopie in sich vereint. Er spitzt Fragen um Transparenz, Privatsphäre, Demokratie und die panoptischen Tendenzen von Big Data im Stile einer Science-Fiction gelungen zu. Antwort: unbedingt!

In Dave Eggers Roman „The Circle“ treffen sich Kumpelchef und Hyperkapitalismus. Quelle: Wikimedia.
Links und Quellen:
Brin, Sergey. Page, Lawrence: The Anatomy of a Large-Scale Hypertextual Web Search Engine, Stanford 1994
Battelle, John: How Google and Its Rivals Rewrote the Rules of Business and Transformed Our Culture, New York 2005
Vaidhyanathan, Siva: The Googlization of Everything. And Why We Should Worry, University of California Press, Berkeley 2011
Levy, Steven: In The Plex: How Google Thinks, Works, and Shapes Our Lives, Simon & Schuster, New York 2011
Pariser, Eli: The Filter Bubble, London 2011
50 Amazing Facts and Figures About Google
Google Annual Search Statistics
Eggers, Dave: The Circle, San Francisco 2013
Zur Übersicht aller Texte der Reihe »Understanding Digital Capitalism«.
Timo Daum arbeitet als Dozent in den Bereichen Online, Medien und Digitale Ökonomie. Zum Thema Understanding Digital Capitalism fand vor einiger Zeit eine Veranstaltungsreihe in Berlin statt.







{kind=link}
{kind=link}
{kind=link}
{kind=link}